Replicating the Gürkaynak, Sack, and Wright (2006) Treasury Yield Curve#
Introduction#
In this section, we’ll explore how to replicate the U.S. Treasury yield curve estimation methodology developed by Gürkaynak, Sack, and Wright (2006) (hereafter GSW). The GSW yield curve has become a standard benchmark in both academic research and industry practice. Their approach provides daily estimates of the U.S. Treasury yield curve from 1961 to the present, making it an invaluable resource for analyzing historical interest rate dynamics.
The Nelson-Siegel-Svensson Model#
The GSW methodology employs the Nelson-Siegel-Svensson (NSS) model to fit the yield curve. The NSS model expresses instantaneous forward rates using a flexible functional form with six parameters:
Example: NSS Forward Rate Function The instantaneous forward rate n years ahead is given by:
This specification allows for rich curve shapes while maintaining smoothness and asymptotic behavior. The parameters have intuitive interpretations:
\(\beta_1\): The asymptotic forward rate
\(\beta_2\), \(\beta_3\), \(\beta_4\): Control the shape and humps of the curve
\(\tau_1\), \(\tau_2\): Determine the location of curve features
This equation shows the zero-coupon yield \(y(t)\) for maturity \(t\).
import pandas as pd
import numpy as np
import pull_CRSP_treasury
import pull_yield_curve_data
import gsw2006_yield_curve
from settings import config
DATA_DIR = config("DATA_DIR")
# Nelson-Siegel-Svensson parameters
# "tau1", "tau2", "beta1", "beta2", "beta3", "beta4"
params = np.array([1.0, 10.0, 3.0, 3.0, 3.0, 3.0])
gsw2006_yield_curve.plot_spot_curve(params);
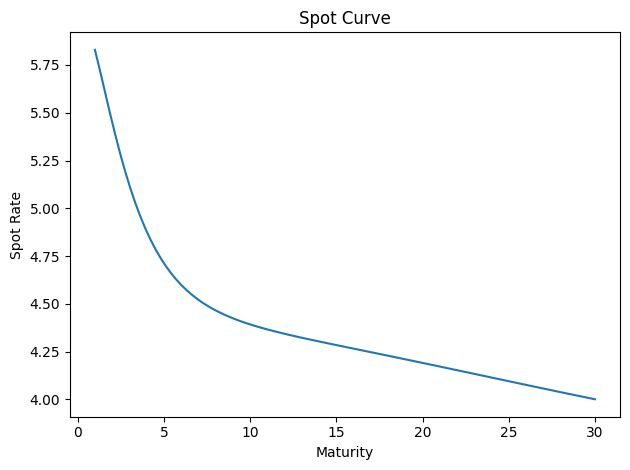
# Nelson-Siegel-Svensson parameters
# "tau1", "tau2", "beta1", "beta2", "beta3", "beta4"
params = np.array([1.0, 10.0, 3.0, 3.0, 3.0, 30.0])
gsw2006_yield_curve.plot_spot_curve(params);
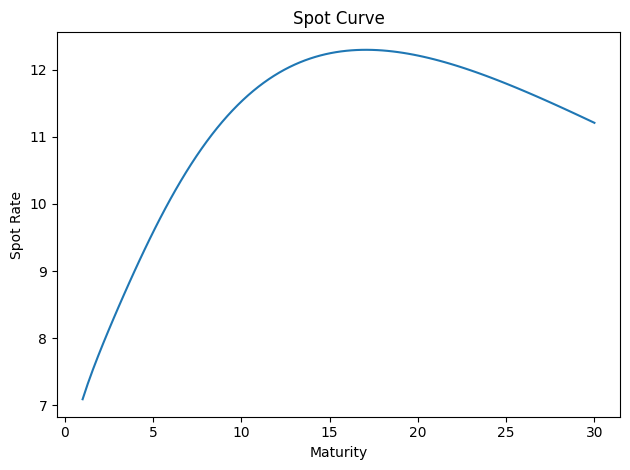
Theoretical Foundations#
The Nelson-Siegel-Svensson model is commonly used in practice to fit the yield curve. It has statistically appealing properties, but it is not arbitrage-free. Here’s a detailed breakdown of why:
1. Static Curve-Fitting Approach#
The NSS model is primarily a parametric curve-fitting tool that focuses on matching observed yields at a single point in time.
It does not model the dynamic evolution of interest rates or enforce consistency between short-term rate expectations and long-term yields over time, a key requirement for no-arbitrage models.
2. Absence of No-Arbitrage Restrictions#
No-arbitrage models impose constraints to prevent risk-free profits. For example, affine term structure models derive bond prices from:
\[ P(t,T) = \mathbb{E}^\mathbb{Q}\left[e^{-\int_t^T r_s ds}\right], \]where \(\mathbb{Q}\) is the risk-neutral measure. The NSS model lacks such theoretical foundations.
The NSS parameters (e.g., level, slope, curvature) are statistically estimated rather than derived from economic principles or arbitrage-free dynamics.
4. Contrast with Arbitrage-Free Extensions#
The arbitrage-free Nelson-Siegel (AFNS) model, developed by Christensen et al. (2007), addresses these limitations by:
Embedding Nelson-Siegel factors into a dynamic arbitrage-free framework.
Explicitly defining factor dynamics under both physical (\(\mathbb{P}\)) and risk-neutral (\(\mathbb{Q}\)) measures.
Ensuring internal consistency between yields of different maturities.
5. Empirical vs. Theoretical Focus#
The NSS model prioritizes empirical flexibility (e.g., fitting yield curve shapes like humps) over theoretical rigor. While it performs well in practice, this trade-off inherently sacrifices no-arbitrage guarantees.
In summary, the NSS model’s lack of dynamic factor specifications, absence of explicit no-arbitrage constraints, and focus on cross-sectional fitting rather than intertemporal consistency render it theoretically incompatible with arbitrage-free principles. Its successors, such as the AFNS model, bridge this gap by integrating no-arbitrage restrictions while retaining empirical tractability.
Data Filtering#
One important step of the GSW methodology is careful filtering of Treasury securities.
The following filters are implemented:
Exclude securities with < 3 months to maturity
Exclude on-the-run and first off-the-run issues after 1980
Exclude T-bills (only keep notes and bonds)
Exclude 20-year bonds after 1996 with decay
Exclude callable bonds
The GSW paper also includes ad hoc exclusions for specific issues, which are not implemented here.
Why are these filters important?
For (2), this is what the paper says:
We exclude the two most recently issued securities with maturities of two, three, four, five, seven, ten, twenty, and thirty years for securities issued in 1980 or later. These are the “on-the-run” and “first off-the-run” issues that often trade at a premium to other Treasury securities, owing to their greater liquidity and their frequent specialness in the repo market.8 Earlier in the sample, the concept of an on-the-run issue was not well defined, since the Treasury did not conduct regular auctions and the repo market was not well developed (as discussed by Garbade (2004)). Our cut-off point for excluding onthe- run and first off-the-run issues is somewhat arbitrary but is a conservative choice (in the sense of potentially erring on the side of being too early).
For (4), this is what the paper says:
We begin to exclude twenty-year bonds in 1996, because those securities often appeared cheap relative to ten-year notes with comparable duration. This cheapness could reflect their lower liquidity or the fact that their high coupon rates made them unattractive to hold for tax-related reasons.
To avoid an abrupt change to the sample, we allow their weights to linearly decay from 1 to 0 over the year ending on January 2, 1996.
Let’s examine how we implement these filters using CRSP data. The following is
from the pull_CRSP_treasury.py file:
def gurkaynak_sack_wright_filters(dff):
"""Apply Treasury security filters based on Gürkaynak, Sack, and Wright (2006).
"""
df = dff.copy()
# Filter 1: Exclude < 3 months to maturity
df = df[df["days_to_maturity"] > 92]
# Filter 2: Exclude on-the-run and first off-the-run after 1980
post_1980 = df["caldt"] >= pd.to_datetime("1980-01-01")
df = df[~(post_1980 & (df["run"] <= 2))]
# Filter 3: Only include notes (2) and bonds (1)
df = df[df["itype"].isin([1, 2])]
# Filter 4: Exclude 20-year bonds after 1996 with decay
cutoff_date = pd.to_datetime("1996-01-02")
decay_start = cutoff_date - pd.DateOffset(years=1)
df["weight"] = 1.0
# Apply linear decay only during 1995-01-02 to 1996-01-02
mask_decay = (
(df["original_maturity"] == 20)
& (df["caldt"] >= decay_start)
& (df["caldt"] <= cutoff_date)
)
# Calculate proper decay factor for the transition year
decay_days = (cutoff_date - decay_start).days
decay_factor = 1 - ((df["caldt"] - decay_start).dt.days / decay_days)
df.loc[mask_decay, "weight"] *= decay_factor
# Completely exclude 20-year bonds after cutoff date
mask_exclude = (df["original_maturity"] == 20) & (df["caldt"] > cutoff_date)
df.loc[mask_exclude, "weight"] = 0
# Filter 5: Exclude callable bonds
df = df[~df["callable"]]
# Remove securities with zero/negative weights
df = df[df["weight"] > 0]
return df
Let’s examine how this affects the data.
## Load Gurkaynak Sack Wright data from Federal Reserve's website
# See here: https://www.federalreserve.gov/data/nominal-yield-curve.htm
# and here: https://www.federalreserve.gov/data/yield-curve-tables/feds200628_1.html
actual_all = pull_yield_curve_data.load_fed_yield_curve_all(data_dir=DATA_DIR)
# Create copy of parameter DataFrame to avoid view vs copy issues
actual_params_all = actual_all.loc[
:, ["TAU1", "TAU2", "BETA0", "BETA1", "BETA2", "BETA3"]
].copy()
# Convert percentage points to decimals for beta parameters
beta_columns = ["BETA0", "BETA1", "BETA2", "BETA3"]
actual_params_all[beta_columns] = actual_params_all[beta_columns] / 100
## Load CRSP Treasury data from Wharton Research Data Services
# We will fit a Nelson-Siegel-Svensson model to this data to see
# if we can replicate the Gurkaynak Sack Wright results above.
df_all = pull_CRSP_treasury.load_CRSP_treasury_consolidated(data_dir=DATA_DIR)
df_all.tail()
| kytreasno | kycrspid | tcusip | caldt | tdatdt | tmatdt | tfcaldt | tdbid | tdask | tdaccint | ... | price | tcouprt | itype | original_maturity | years_to_maturity | tdduratn | tdretnua | days_to_maturity | callable | run | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2444132 | 208334.0 | 20291231.204370 | 91282CMD | 2024-12-27 | 2024-12-31 | 2029-12-31 | 0 | 99.617188 | 99.625000 | 0.0 | ... | 99.621094 | 4.375 | 2.0 | 5.0 | 5.0 | 1663.241322 | -0.001331 | 1830 | False | 0 |
| 2444133 | 208334.0 | 20291231.204370 | 91282CMD | 2024-12-30 | 2024-12-31 | 2029-12-31 | 0 | 100.015625 | 100.023438 | 0.0 | ... | 100.019531 | 4.375 | 2.0 | 5.0 | 5.0 | 1660.609119 | 0.004000 | 1827 | False | 0 |
| 2444134 | 208334.0 | 20291231.204370 | 91282CMD | 2024-12-31 | 2024-12-31 | 2029-12-31 | 0 | 99.949764 | 99.957577 | 0.0 | ... | 99.953671 | 4.375 | 2.0 | 5.0 | 5.0 | 1659.530417 | -0.000658 | 1826 | False | 0 |
| 2444135 | 208335.0 | 20311231.204500 | 91282CMC | 2024-12-30 | 2024-12-31 | 2031-12-31 | 0 | 100.265625 | 100.281250 | 0.0 | ... | 100.273438 | 4.500 | 2.0 | 7.0 | 7.0 | 2222.076359 | NaN | 2557 | False | 0 |
| 2444136 | 208335.0 | 20311231.204500 | 91282CMC | 2024-12-31 | 2024-12-31 | 2031-12-31 | 0 | 100.083247 | 100.098872 | 0.0 | ... | 100.091059 | 4.500 | 2.0 | 7.0 | 7.0 | 2220.681438 | -0.001819 | 2556 | False | 0 |
5 rows × 21 columns
df_all.describe()
| kytreasno | caldt | tdatdt | tmatdt | tfcaldt | tdbid | tdask | tdaccint | tdyld | price | tcouprt | itype | original_maturity | years_to_maturity | tdduratn | tdretnua | days_to_maturity | run | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 2.444137e+06 | 2444137 | 2444137 | 2444137 | 2444137.0 | 2.444093e+06 | 2.444093e+06 | 2.444137e+06 | 2.444093e+06 | 2.444093e+06 | 2.444137e+06 | 2.444137e+06 | 2.444137e+06 | 2.444137e+06 | 2.444137e+06 | 2.442115e+06 | 2.444137e+06 | 2.444137e+06 |
| mean | 2.044759e+05 | 2004-05-19 21:05:09.422099968 | 1999-07-19 03:10:44.848467840 | 2010-07-22 08:13:12.568338176 | 0.0 | 1.047043e+02 | 1.047902e+02 | 1.355873e+00 | 1.207134e-04 | 1.061031e+02 | 5.448518e+00 | 1.748902e+00 | 1.099878e+01 | 6.177746e+00 | 1.643023e+03 | 1.994802e-04 | 2.254464e+03 | 1.881510e+01 |
| min | 2.006360e+05 | 1970-01-02 00:00:00 | 1955-02-15 00:00:00 | 1970-02-15 00:00:00 | 0.0 | 4.350000e+01 | 4.354688e+01 | 0.000000e+00 | -1.664162e-02 | 4.405673e+01 | 1.250000e-01 | 1.000000e+00 | 1.000000e+00 | 0.000000e+00 | -1.000000e+00 | -1.094112e-01 | 1.000000e+00 | 0.000000e+00 |
| 25% | 2.028010e+05 | 1992-04-03 00:00:00 | 1986-12-03 00:00:00 | 1996-09-30 00:00:00 | 0.0 | 9.910938e+01 | 9.917969e+01 | 3.532609e-01 | 4.683062e-05 | 9.990217e+01 | 2.375000e+00 | 1.000000e+00 | 5.000000e+00 | 1.000000e+00 | 5.100068e+02 | -5.757035e-04 | 5.260000e+02 | 5.000000e+00 |
| 50% | 2.040500e+05 | 2007-05-04 00:00:00 | 1998-11-15 00:00:00 | 2014-03-31 00:00:00 | 0.0 | 1.010547e+02 | 1.011172e+02 | 9.191576e-01 | 1.159452e-04 | 1.024460e+02 | 5.000000e+00 | 2.000000e+00 | 7.000000e+00 | 3.000000e+00 | 1.108149e+03 | 1.431182e-04 | 1.208000e+03 | 1.400000e+01 |
| 75% | 2.065920e+05 | 2017-05-30 00:00:00 | 2013-02-28 00:00:00 | 2022-08-15 00:00:00 | 0.0 | 1.067812e+02 | 1.068594e+02 | 2.013467e+00 | 1.736904e-04 | 1.085687e+02 | 7.875000e+00 | 2.000000e+00 | 1.000000e+01 | 7.000000e+00 | 2.150573e+03 | 1.021177e-03 | 2.536000e+03 | 2.800000e+01 |
| max | 2.083350e+05 | 2024-12-31 00:00:00 | 2024-12-31 00:00:00 | 2054-11-15 00:00:00 | 0.0 | 1.763281e+02 | 1.763906e+02 | 1.186908e+01 | 6.557793e-03 | 1.827193e+02 | 1.625000e+01 | 2.000000e+00 | 4.000000e+01 | 3.000000e+01 | 9.160067e+03 | 1.281108e-01 | 1.105300e+04 | 8.400000e+01 |
| std | 2.027969e+03 | NaN | NaN | NaN | 0.0 | 1.304764e+01 | 1.302720e+01 | 1.309228e+00 | 8.890701e-05 | 1.342238e+01 | 3.586926e+00 | 4.336449e-01 | 9.959075e+00 | 7.380510e+00 | 1.624650e+03 | 3.684351e-03 | 2.689590e+03 | 1.767407e+01 |
df_all = gsw2006_yield_curve.gurkaynak_sack_wright_filters(df_all)
df_all.describe()
| kytreasno | caldt | tdatdt | tmatdt | tfcaldt | tdbid | tdask | tdaccint | tdyld | price | tcouprt | itype | original_maturity | years_to_maturity | tdduratn | tdretnua | days_to_maturity | run | weight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 2.047468e+06 | 2047468 | 2047468 | 2047468 | 2047468.0 | 2.047462e+06 | 2.047462e+06 | 2.047468e+06 | 2.047462e+06 | 2.047462e+06 | 2.047468e+06 | 2.047468e+06 | 2.047468e+06 | 2.047468e+06 | 2.047468e+06 | 2.047282e+06 | 2.047468e+06 | 2.047468e+06 | 2.047468e+06 |
| mean | 2.045261e+05 | 2004-11-24 19:14:20.588394624 | 1999-12-29 16:16:07.118410880 | 2010-12-26 22:20:38.496718848 | 0.0 | 1.051147e+02 | 1.051976e+02 | 1.315912e+00 | 1.172641e-04 | 1.064721e+02 | 5.314009e+00 | 1.760971e+00 | 1.098118e+01 | 6.091611e+00 | 1.639427e+03 | 1.952504e-04 | 2.223129e+03 | 2.065100e+01 | 9.992132e-01 |
| min | 2.006560e+05 | 1970-01-02 00:00:00 | 1955-02-15 00:00:00 | 1970-05-15 00:00:00 | 0.0 | 4.350000e+01 | 4.354688e+01 | 0.000000e+00 | -4.305986e-05 | 4.405673e+01 | 1.250000e-01 | 1.000000e+00 | 1.000000e+00 | 0.000000e+00 | -1.000000e+00 | -1.094112e-01 | 9.300000e+01 | 0.000000e+00 | 1.095890e-02 |
| 25% | 2.028440e+05 | 1992-10-06 00:00:00 | 1987-08-15 00:00:00 | 1997-03-31 00:00:00 | 0.0 | 9.904688e+01 | 9.910938e+01 | 3.519022e-01 | 4.453181e-05 | 9.989436e+01 | 2.250000e+00 | 2.000000e+00 | 5.000000e+00 | 1.000000e+00 | 5.210182e+02 | -5.814131e-04 | 5.400000e+02 | 8.000000e+00 | 1.000000e+00 |
| 50% | 2.040600e+05 | 2008-11-03 00:00:00 | 2000-03-31 00:00:00 | 2015-07-15 00:00:00 | 0.0 | 1.014648e+02 | 1.015273e+02 | 8.981354e-01 | 1.121552e-04 | 1.027308e+02 | 4.750000e+00 | 2.000000e+00 | 7.000000e+00 | 3.000000e+00 | 1.111342e+03 | 1.428802e-04 | 1.203000e+03 | 1.600000e+01 | 1.000000e+00 |
| 75% | 2.066220e+05 | 2017-10-05 00:00:00 | 2013-05-15 00:00:00 | 2022-10-31 00:00:00 | 0.0 | 1.073906e+02 | 1.074609e+02 | 1.944293e+00 | 1.710489e-04 | 1.091391e+02 | 7.875000e+00 | 2.000000e+00 | 1.000000e+01 | 7.000000e+00 | 2.096096e+03 | 1.010312e-03 | 2.440000e+03 | 2.900000e+01 | 1.000000e+00 |
| max | 2.082900e+05 | 2024-12-31 00:00:00 | 2024-09-30 00:00:00 | 2054-02-15 00:00:00 | 0.0 | 1.763281e+02 | 1.763906e+02 | 1.186908e+01 | 9.394247e-04 | 1.827193e+02 | 1.625000e+01 | 2.000000e+00 | 4.000000e+01 | 2.900000e+01 | 8.738464e+03 | 1.281108e-01 | 1.069200e+04 | 8.100000e+01 | 1.000000e+00 |
| std | 2.030425e+03 | NaN | NaN | NaN | 0.0 | 1.334655e+01 | 1.332798e+01 | 1.261735e+00 | 8.556826e-05 | 1.371406e+01 | 3.499509e+00 | 4.264908e-01 | 9.904625e+00 | 7.189806e+00 | 1.598785e+03 | 3.589804e-03 | 2.621508e+03 | 1.719935e+01 | 2.278002e-02 |
Implementation Steps#
1. Data Preparation#
First, we load and clean the CRSP Treasury data
df_all = pull_CRSP_treasury.load_CRSP_treasury_consolidated(data_dir=DATA_DIR)
2. Cashflow Construction#
For each Treasury security, we need to calculate its future cashflows. Consider the following simplified example:
sample_data = pd.DataFrame(
{
"tcusip": ["A", "B", "C", "D", "E"],
"tmatdt": pd.to_datetime(
["2000-05-15", "2000-05-31", "2000-06-30", "2000-07-31", "2000-08-15"]
),
"price": [101, 101, 100, 100, 103],
"tcouprt": [6, 6, 0, 5, 6],
"caldt": pd.to_datetime("2000-01-31"),
}
)
cashflow = gsw2006_yield_curve.calc_cashflows(sample_data)
# Treasury securities have 2 coupon payments per year
# and pay their final coupon and principal on the maturity date
expected_cashflow = np.array(
[
[0.0, 103.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 103.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 100.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 102.5, 0.0],
[3.0, 0.0, 0.0, 0.0, 0.0, 103.0],
]
)
cashflow
| 2000-02-15 | 2000-05-15 | 2000-05-31 | 2000-06-30 | 2000-07-31 | 2000-08-15 | |
|---|---|---|---|---|---|---|
| 0 | 0.0 | 103.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 103.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 100.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 102.5 | 0.0 |
| 4 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 103.0 |
3. Model Fitting#
The NSS model is fit by minimizing price errors weighted by duration:
where:
\(P_i^{obs}\) = Observed clean price (including accrued interest)
\(P_i^{model}\) = Model-implied price
\(D_i\) = Duration of security i
Now, why are the squared errors weighted by the duration?
Recall that bond duration is a measurement of how much a bond’s price will change in response to interest rate changes. Thus, the price error objective is approximately equivalent to minimizing unweighted yield errors:
This approximation comes from the duration relationship: $\( P^{obs} - P^{model} \approx -D \cdot (y^{obs} - y^{model}) \)$
Making the objective function: $\( \sum D_i \cdot (y_i^{obs} - y_i^{model})^2 \)$
So, why Price Errors Instead of Yield Errors?
Non-linear relationship: The price/yield relationship is convex (convexity adjustment matters more for long-duration bonds)
Coupon effects: Directly accounts for differential cash flow timing
Numerical stability: Prices have linear sensitivity to parameters via discount factors, while yields require non-linear root-finding
Economic meaning: Aligns with trader behavior that thinks in terms of price arbitrage
Reference: Gurkaynak, Sack, and Wright (2006)
Note#
Note that the paper says the following:
In estimating the yield curve, we choose the parameters to minimize the weighted sum of the squared deviations between the actual prices of Treasury securities and the predicted prices. The weights chosen are the inverse of the duration of each individual security. To a rough approximation, the deviation between the actual and predicted prices of an individual security will equal its duration multiplied by the deviation between the actual and predicted yields. Thus, this procedure is approximately equal to minimizing the (unweighted) sum of the squared deviations between the actual and predicted yields on all of the securities.
However, I need to check this further since it initially seems to me that this procedure is minimizing the squared yield errors, weighted by the duration. However, the fit to actual prices seems better with the procedure above. I need to check this further.
Testing and Validation#
To validate our implementation, we compare our fitted yields against the official GSW yields published by the Federal Reserve:
## Load Gurkaynak Sack Wright data from Federal Reserve's website
# See here: https://www.federalreserve.gov/data/nominal-yield-curve.htm
# and here: https://www.federalreserve.gov/data/yield-curve-tables/feds200628_1.html
actual_all = pull_yield_curve_data.load_fed_yield_curve_all(data_dir=DATA_DIR)
# Create copy of parameter DataFrame to avoid view vs copy issues
actual_params_all = actual_all.loc[
:, ["TAU1", "TAU2", "BETA0", "BETA1", "BETA2", "BETA3"]
].copy()
# Convert percentage points to decimals for beta parameters
beta_columns = ["BETA0", "BETA1", "BETA2", "BETA3"]
actual_params_all[beta_columns] = actual_params_all[beta_columns] / 100
## Load CRSP Treasury data from Wharton Research Data Services
# We will fit a Nelson-Siegel-Svensson model to this data to see
# if we can replicate the Gurkaynak Sack Wright results above.
df_all = pull_CRSP_treasury.load_CRSP_treasury_consolidated(data_dir=DATA_DIR)
df_all = gsw2006_yield_curve.gurkaynak_sack_wright_filters(df_all)
quote_dates = pd.date_range("2000-01-02", "2024-06-30", freq="BMS")
# quote_date = quote_dates[-1]
## Test Day 1
quote_date = pd.to_datetime("2024-06-03")
# Subset df_all to quote_date
df = df_all[df_all["caldt"] == quote_date]
actual_params = actual_params_all[actual_params_all.index == quote_date].values[0]
# "tau1", "tau2", "beta1", "beta2", "beta3", "beta4"
# params0 = np.array([1.0, 10.0, 3.0, 3.0, 3.0, 3.0])
params0 = np.array([0.989721, 9.955324, 3.685087, 1.579927, 3.637107, 9.814584])
# params0 = np.array([1.0, 1.0, 0.001, 0.001, 0.001, 0.001])
params_star, error = gsw2006_yield_curve.fit(quote_date, df_all, params0)
## Visualize the fit
gsw2006_yield_curve.plot_spot_curve(params_star)
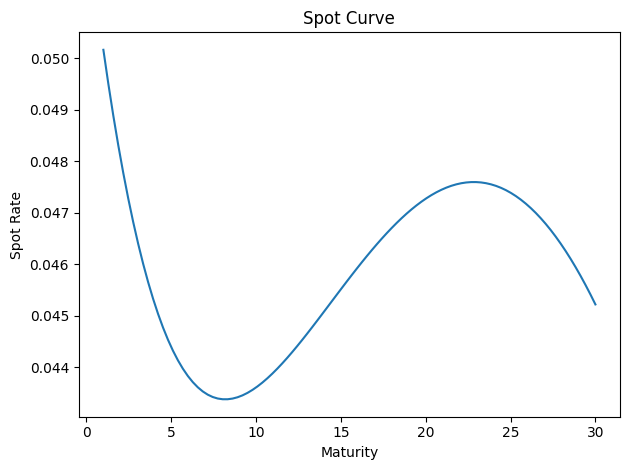
<Axes: title={'center': 'Spot Curve'}, xlabel='Maturity', ylabel='Spot Rate'>
gsw2006_yield_curve.plot_spot_curve(actual_params)
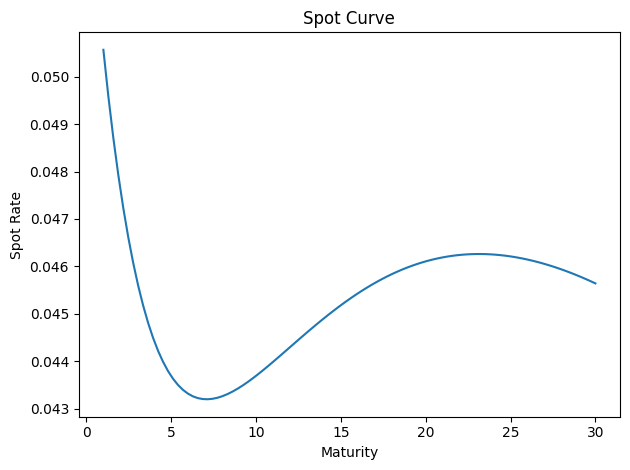
<Axes: title={'center': 'Spot Curve'}, xlabel='Maturity', ylabel='Spot Rate'>
price_comparison = gsw2006_yield_curve.compare_fit(
quote_date, df_all, params_star, actual_params, df
)
price_comparison
| Actual Price | GSW Predicted Price | Model Predicted Price | Predicted - Actual % | Predicted - GSW % | |
|---|---|---|---|---|---|
| tcusip | |||||
| 912810ET | 104.189560 | 103.877734 | 103.934496 | -0.002448 | 0.000546 |
| 912810EV | 104.504035 | 104.146501 | 104.170139 | -0.003195 | 0.000227 |
| 912810EW | 103.835766 | 103.539602 | 103.500473 | -0.003229 | -0.000378 |
| 912810EX | 106.232229 | 106.071133 | 105.960580 | -0.002557 | -0.001042 |
| 912810EY | 105.202785 | 104.356538 | 104.209717 | -0.009440 | -0.001407 |
| ... | ... | ... | ... | ... | ... |
| 91282CJW | 99.132169 | 99.440209 | 99.129012 | -0.000032 | -0.003129 |
| 91282CJX | 98.413419 | 99.124083 | 98.901003 | 0.004954 | -0.002251 |
| 91282CKB | 100.744735 | 100.757545 | 100.713047 | -0.000315 | -0.000442 |
| 91282CKD | 99.929178 | 100.242964 | 99.930006 | 0.000008 | -0.003122 |
| 91282CKC | 100.226053 | 100.302116 | 100.082336 | -0.001434 | -0.002191 |
292 rows × 5 columns
## Assert that column is close to 0 for all CUSIPs
assert (price_comparison["Predicted - Actual %"].abs() < 0.05).all()
assert (price_comparison["Predicted - GSW %"].abs() < 0.02).all()
## Test Day 2
quote_date = pd.to_datetime("2000-06-05")
# Subset df_all to quote_date
df = df_all[df_all["caldt"] == quote_date]
actual_params = actual_params_all[actual_params_all.index == quote_date].values[0]
# "tau1", "tau2", "beta1", "beta2", "beta3", "beta4"
# params0 = np.array([1.0, 10.0, 3.0, 3.0, 3.0, 3.0])
params0 = np.array([0.989721, 9.955324, 3.685087, 1.579927, 3.637107, 9.814584])
# params0 = np.array([1.0, 1.0, 0.001, 0.001, 0.001, 0.001])
params_star, error = gsw2006_yield_curve.fit(quote_date, df_all, params0)
## Visualize the fit
# gsw2006_yield_curve.plot_spot_curve(params_star)
# gsw2006_yield_curve.plot_spot_curve(actual_params)
price_comparison = gsw2006_yield_curve.compare_fit(
quote_date, df_all, params_star, actual_params, df
)
## Assert that column is close to 0 for all CUSIPs
assert (price_comparison["Predicted - Actual %"].abs() < 0.05).all()
assert (price_comparison["Predicted - GSW %"].abs() < 0.02).all()
## Test Day 3
quote_date = pd.to_datetime("1990-06-05")
# Subset df_all to quote_date
df = df_all[df_all["caldt"] == quote_date]
actual_params = actual_params_all[actual_params_all.index == quote_date].values[0]
# "tau1", "tau2", "beta1", "beta2", "beta3", "beta4"
# params0 = np.array([1.0, 10.0, 3.0, 3.0, 3.0, 3.0])
params0 = np.array([0.989721, 9.955324, 3.685087, 1.579927, 3.637107, 9.814584])
# params0 = np.array([1.0, 1.0, 0.001, 0.001, 0.001, 0.001])
params_star, error = gsw2006_yield_curve.fit(quote_date, df_all, params0)
## Visualize the fit
# gsw2006_yield_curve.plot_spot_curve(params_star)
# gsw2006_yield_curve.plot_spot_curve(actual_params)
price_comparison = gsw2006_yield_curve.compare_fit(
quote_date, df_all, params_star, actual_params, df
)
## Assert that column is close to 0 for all CUSIPs
assert (price_comparison["Predicted - Actual %"].abs() < 0.05).all()
assert (price_comparison["Predicted - GSW %"].abs() < 0.02).all()
Conclusion#
The GSW yield curve methodology provides a robust framework for estimating the U.S. Treasury yield curve. By carefully implementing their filtering criteria and optimization approach, we can replicate their results with high accuracy. This implementation allows us to extend their analysis to current data and provides a foundation for various fixed-income applications.
Example: Model Performance Our implementation typically achieves price errors below 0.02% compared to the official GSW yields, demonstrating the reliability of the replication.