What is a build system or task runner?#
Introduction to Build Systems and Task Runners#
A build system is a collection of tools and scripts that automate the process of compiling source code into executable programs or libraries. It can handle tasks like tracking dependencies between files, compiling source code in the necessary sequence, and executing unit tests. Build systems are crucial in software development, especially in large projects with numerous source files and complex dependency chains. Make and Makefiles are a common example of a build system.
A task runner is similar. It is a software utility designed to automate the execution of repetitive tasks in the software development process. These tasks can include but are not limited to, scripting routine operations such as minifying code, running tests, compiling source files, and deploying to production servers. Task runners streamline the workflow by reducing the need for manual intervention, enhancing consistency, and saving valuable time. They are particularly beneficial in complex projects where the frequency and complexity of these tasks can be substantial. By defining a series of tasks and their respective commands in a configuration file, task runners enable developers to execute complex sequences with simple commands, thus improving efficiency and productivity in the development lifecycle.
Note that here I will sometimes use these phrases interchangeably, though they are somewhat different. Some build systems can be used as task runners, and some task runners can be used as build systems.
A task runner in this context addresses multiple challenges:
Workflow Management: Manages the execution order of various scripts and notebooks based on dependencies.
Data Integrity: Ensures that any changes in data or scripts trigger the re-run of dependent tasks, maintaining data integrity.
Reproducibility: Facilitates reproducibility of results, crucial in research settings, by automating the workflow.
Resource Efficiency: Saves computational resources by only re-running tasks whose dependencies have changed.
Collaboration: Aids in team collaboration by providing a standardized way to run and reproduce the entire workflow.
Discussion
When working on a large coding project, have you ever stepped away for a few weeks and then tried to return to the project only to find difficulty remembering the steps you used to get the results you had before?
Or, even if you took the time to document the steps you used to get the results you had before, have you ever found that the steps you used to get the results you had before are no longer valid? (task runners are self-documenting)
Suppose you are trying to manage a complex data science workflow in a research setting. In a finance research setting, a data science project often involves several interdependent stages: data collection, preprocessing, analysis, model training, validation, and reporting. Each stage may depend on the output of the previous stages, and the project might include a mix of Python scripts, Jupyter notebooks, and data files in various formats.
Simple Workflow
The following flow chart represents a simple data science workflow. Each step depends on the previous step. It starts with data collection, then preprocessing, then analysis, then model training, then validation, and finally reporting. If one of the early steps in changed, all steps after it will need to be re-run.

Complex Workflow, represented as a directed acyclic graph (DAG)
The following is a hypothetical workflow that is more complex than the simple workflow above.
Such workflows can, without loss of generality, be represented as a directed acyclic graph (DAG).
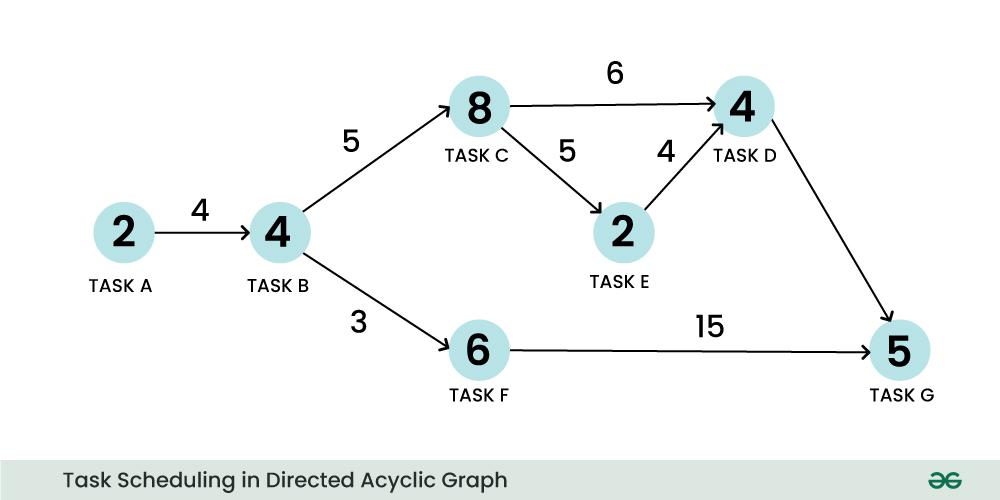
Mapping Tasks into DAGs is a Key Insight into Parallelizing Workflows
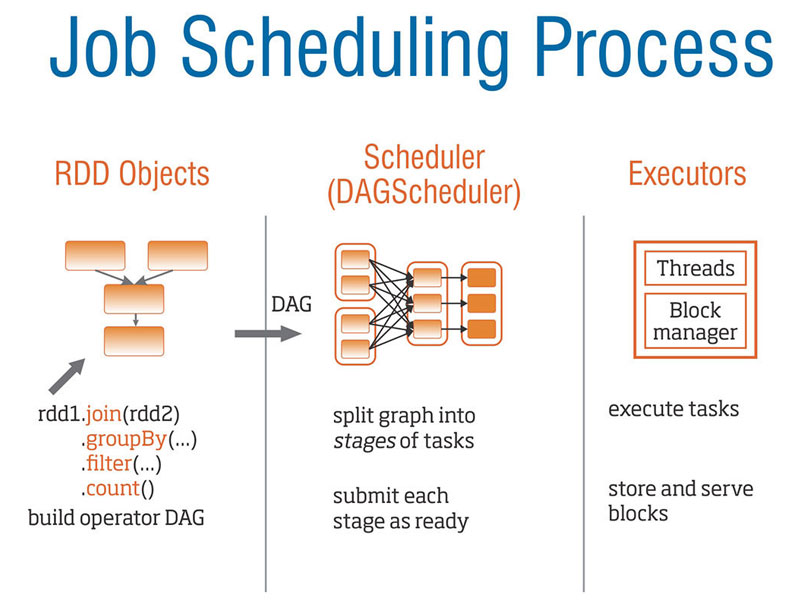
The following figure demonstrates how PySpark represents a workflow as a DAG,
which in combination with a job scheduler, allows for parallelizing the workflow.
Representing your workflow as a DAG can help you to identify opportunities to parallelize your workflow.
Example of a Task Runner/Build System Managing a Project#
Consider as an example, the simple data science workflow we discussed above.
Suppose that we have a hypothetical project that completes runs a set of abstract tasks:
data collection, preprocessing, analysis, model training, validation, and reporting.
Each of these tasks depend on the previous task.
As an example, a build system might have a file that manages a project that looks like this.
This script is a file called dodo.py that uses the PyDoit Python-based build system.
The task runner script documents the scripts associated with each step as follows:
Data Collection: A script (
data_collection.py) gathers financial data from various sources.Dependencies: None
Output:
data/raw_data.csv
Preprocessing: Another script (
preprocess.py) cleans and preprocesses the data.Dependencies:
data/raw_data.csvOutput:
data/processed_data.csv
Analysis: A Jupyter notebook (
analysis.ipynb) performs data analysis.Dependencies:
data/processed_data.csvOutput:
reports/analysis_output.html
Model Training: A script (
train_model.py) trains the model.Dependencies:
data/processed_data.csvOutput:
models/trained_model.pkl
Validation: A script (
validate_model.py) validates the trained model.Dependencies:
models/trained_model.pklOutput:
reports/validation_report.txt
Reporting: A script (
generate_report.py) compiles the results into a report.Dependencies:
reports/analysis_output.html,reports/validation_report.txtOutput:
reports/final_report.pdf
The dodo.py script then looks like this:
# dodo.py for managing a data scinece research project workflow
def task_data_collection():
return {
'file_dep': [],
'actions': ['python scripts/data_collection.py'],
'targets': ['data/raw_data.csv'],
}
def task_preprocessing():
return {
'file_dep': ['data/raw_data.csv'],
'actions': ['python scripts/preprocess.py'],
'targets': ['data/processed_data.csv'],
}
def task_analysis():
return {
'file_dep': ['data/processed_data.csv'],
'actions': ['jupyter nbconvert --execute notebooks/analysis.ipynb'],
'targets': ['reports/analysis_output.html'],
}
def task_model_training():
return {
'file_dep': ['data/processed_data.csv'],
'actions': ['python scripts/train_model.py'],
'targets': ['models/trained_model.pkl'],
}
def task_validation():
return {
'file_dep': ['models/trained_model.pkl'],
'actions': ['python scripts/validate_model.py'],
'targets': ['reports/validation_report.txt'],
}
def task_reporting():
return {
'file_dep': ['reports/analysis_output.html', 'reports/validation_report.txt'],
'actions': ['python scripts/generate_report.py'],
'targets': ['reports/final_report.pdf'],
}
In this dodo.py:
Each
task_function defines a stage in the workflow. Each function must start withtask_if it is to be recognized as a task by the task runner. Each function returns a dictionary with the keys'actions','file_dep', and'targets'.The
'actions'key specifies the command to run for each task.The
'file_dep'(file dependencies) key lists the files that the task depends on.The
'targets'key lists the files that the task produces.
With this setup, the entire workflow can be automated and executed in the correct order with a single command (doit), significantly streamlining the research process and ensuring consistency and reproducibility in the results.
This setup ensures that each stage of the workflow is executed in the correct order and only when its dependencies have changed, thereby enhancing efficiency and reproducibility.
Problem Solved by a Build System#
When the project becomes large enough and complex enough, the following problems may arise.
Difficulty in Reproducing Results Without a clear record of the ordering of how the scripts were run, reproducing results becomes challenging. A build system automates the full project from end-to-end and the script managing this workflow itself becomes the documentation of the ordering of the scripts.
Complex Dependency Management In data science, workflows often involve complex dependencies between data, scripts, and models. That is, not only do we have to worry about the order in which to run the scripts, we want to keep track of which script produces or alters each object of interest (intermediate data sets, model files, etc.). A build system manages and resolves dependencies, and itself documents how each object is modified by each script.
Time-Consuming Reruns of Unchanged Steps Rerunning entire workflows after minor changes is time-consuming and inefficient. A build system efficiently identifies and executes only those tasks that are affected by recent changes.
Error Propagation Errors in early stages can propagate unnoticed, affecting subsequent stages. A build system provides a systematic approach to detect errors early by validating outputs at each stage before moving to the next.
Lack of Standardization in Workflow Execution Variability in how different team members execute the workflow can lead to inconsistencies. A build system enforces a standardized process for executing workflows, reducing variability and enhancing collaboration.
Scalability Issues Managing larger datasets or more complex models can become challenging as the project scales. A build system facilitates scaling by automating and optimizing the workflow, making it easier to manage larger or more complex projects. A build system can even help to automatically parallelize the execution of a workflow, since it knows the dependencies and the necessary order needed to execute all the tasks. Python’s
PyDoitsystem provides such features to make this happen automatically, for example.
Documentation and Knowledge Transfer Inadequate documentation can hinder knowledge transfer, especially in large teams or long-term projects. A build system encourages the documentation of workflows, making it easier for new team members to understand and contribute to the project. This is not only beneficial for other team members. Your FUTURE you will thank you. I often forget details of my own workflow, sometimes after only walking away for a week or two. A build system will help you enormously even if you work alone most of the time.
Thus, a build system, by automating and standardizing various aspects of the data science workflow, can significantly mitigate these common pitfalls, leading to more efficient, reproducible, and collaborative research in data science settings.
Make: The most commonly used build system in the world#
Make, e.g. GNU Make, is a widely-used build system that, while particularly prominent in C/C++ projects, offers a versatile toolset extendable to many different programming languages and environments. It functions by automating complex workflows, primarily the compilation process, through the interpretation of a Makefile. This file, central to its operation, details a set of rules and dependencies that guide the build process.
Contrary to a common misconception, Make’s utility is not confined to C/C++ environments. Its capabilities are effectively applicable to a broad spectrum of programming tasks. For instance, it can be used to manage workflows involving scripting languages like Python or R, automate the generation of reports or data files, and even orchestrate complex data analysis pipelines. Its language-agnostic nature allows it to execute arbitrary shell commands, making it a powerful tool for a variety of automation tasks beyond just compilation.
Given its widespread adoption and flexibility, Make is a tool that all data scientists should be at least aware of. Understanding its basic functions can significantly enhance the efficiency of managing various aspects of data science projects. The ability to automate repetitive tasks, ensure consistency in data processing, and manage complex dependencies makes Make an invaluable asset in the toolbox of modern data scientists, regardless of their primary programming language.
Makefile: The Blueprint#
A Makefile is a script utilized by Make, consisting of:
Targets: These are usually file names, representing the output of a build process.
Dependencies: Files that need to be updated before the target can be processed.
Rules: Commands that describe how to update or create a target.
# Sample Makefile
target: dependencies
command to build
Now, consider the dodo.py example file above. When written as a Makefile to be used with Make, it would look like this:
# Makefile for managing a data science research project workflow
# Phony target to handle all tasks
.PHONY: all clean
# Default target
all: reports/final_report.pdf
# Data Collection
data/raw_data.csv:
python scripts/data_collection.py
# Preprocessing
data/processed_data.csv: data/raw_data.csv
python scripts/preprocess.py
# Analysis
reports/analysis_output.html: data/processed_data.csv
jupyter nbconvert --execute notebooks/analysis.ipynb
# Model Training
models/trained_model.pkl: data/processed_data.csv
python scripts/train_model.py
# Validation
reports/validation_report.txt: models/trained_model.pkl
python scripts/validate_model.py
# Reporting
reports/final_report.pdf: reports/analysis_output.html reports/validation_report.txt
python scripts/generate_report.py
# Clean task to remove generated files
clean:
rm -f data/raw_data.csv data/processed_data.csv models/trained_model.pkl
rm -f reports/analysis_output.html reports/validation_report.txt reports/final_report.pdf
In this Makefile:
Each target (like
data/raw_data.csv,data/processed_data.csv, etc.) represents an output of a task.The dependencies for each task (specified after the
:) determine when the task needs to be re-run.The commands under each target (like
python scripts/data_collection.py) are the actions to be performed.The
.PHONYrule is used to define targets that are not associated with files.The
alltarget is the default and will execute the entire workflow, building the final report.The
cleantarget provides a way to remove all generated files, similar to the ‘clean’ function in PyDoit.
This Makefile can be run using the make command to execute the entire workflow or specific tasks, and make clean to clean up the outputs.
Python PyDoit: An Python-based Alternative#
Python PyDoit is a task management and automation tool that offers several advantages, especially for Python-centric workflows, compared to Make:
Ease of Installation with pip or conda:
PyDoit can be conveniently installed using pip, which is a standard tool in Python development.
This contrasts with Make, which, while ubiquitous in Linux environments, may not be readily available on Windows systems without additional installation steps.
The ability to install PyDoit as part of the normal Python environment setup enhances its accessibility and ease of integration into existing Python projects.
Simplified Workflow Description:
PyDoit’s Python-based syntax and structure make it easier to describe and manage complex data science workflows.
Its configuration aligns naturally with the way data scientists typically structure their Python projects, offering a more intuitive approach to task automation.
Consistent Language Ecosystem:
PyDoit is written in Python, which is advantageous for those who write all their code in Python.
This consistency ensures that the entire codebase, including the automation scripts, is in a single, familiar language, reducing the learning curve and increasing the efficiency of managing workflows.
Being in the same language ecosystem as the main project code, PyDoit allows for more seamless integration and utilization of existing Python skills and tools.
Scales down as well as scales up:
While some other task runners may be more feature-rich, this abundance of features can be a hindrance to simple projects.
PyDoit is simple, and can be used for simple projects, or complex projects. For simple projects, PyDoit’s
dodo.pyfile scales down to a few lines of code.
I personally find that these features make PyDoit a particularly attractive option for data scientists and developers who are already immersed in the Python ecosystem and are looking for an effective way to automate their workflows. That said, PyDoit is not ubiquitous. There are many other such systems or task runners, even many others that are written in Python.
Examples of other Build Systems or Task Runners#
Here are some examples of other build systems and/or task runners along with the languages they are typically associated with or the languages they are written in:
Airflow (Apache Airflow): A platform created by Airbnb to programmatically author, schedule, and monitor workflows. While primarily known as a workflow scheduler for data pipelines, it can be used as a sophisticated task runner. It represents workflows as Directed Acyclic Graphs (DAGs) and includes a rich web interface for monitoring and managing tasks.
Bazel (Bazel Home Page): Developed by Google, it supports multiple languages including Java, C++, and Python.
Celery (Celery Home Page): An asynchronous task queue/job queue based on distributed message passing, primarily used in Python applications.
clusterjob (clusterjob docs): A tool for managing computational pipelines in High Performance Computing (HPC) environments. It specializes in submitting and monitoring jobs to cluster job schedulers like SLURM and TORQUE/PBS, making it easier to integrate HPC workflows into computational pipelines. Note that this tool integrates with PyDoit task pipelines (see https://clusterjob.readthedocs.io/en/latest/pydoit_pipeline.html). The tool provides a unified interface for job submission, status monitoring, and resource management across different HPC backend systems.
CMake (CMake Home Page): Widely used for C and C++ projects, but also supports other languages.
Invoke (Invoke Home Page): A task runner written in Python, offering a clean and high-level API for running shell commands and defining/organizing task functions.
joblib (joblib docs): A set of tools to provide lightweight pipelining in Python. Particularly useful for saving computation time and memory when dealing with large data processing tasks through transparent disk-caching and parallel computing.
Luigi (Luigi Home Page): A Python package developed by Spotify that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, and more, making it particularly useful for data engineering and ETL workflows.
PyDoit (PyDoit docs): As discussed above, PyDoit is a Python-based task management and automation tool that offers several advantages for Python-centric workflows. It provides a flexible way to define tasks and their dependencies using Python functions, making it particularly suitable for data science workflows.
pypyr (pypyr Home Page): A task runner written in Python, designed to handle complex workflows by chaining together different tasks.
SCons (SCons Home Page): Written in Python, and used primarily for C, C++, and Fortran projects.
Snakemake (Snakemake): A workflow management system particularly popular in bioinformatics and data science. It’s Python-based and combines the benefits of Make with Python’s flexibility. Uses a Python-based DSL (Domain Specific Language) to define workflows and automatically handles dependency resolution and parallel execution.
PyDoit’s Configuration File: dodo.py#
A dodo.py file in PyDoit is analogous to a Makefile in Make. It defines tasks, which are Python functions or dictionaries, and their dependencies.
# Sample dodo.py
def task_hello():
return {
'actions': ['echo Hello World'],
'file_dep': ['input.txt'],
'targets': ['output.txt'],
}
Example#
For a more complex workflow with PyDoit, see the example at the beginning of this page. To see a working example, examine now the blank_project repository I’ve made available here: jmbejara/blank_project. My template here borrows from the template created by Cookie Cutter Data Science. We’ll now walk through this project, after concluding.
Conclusion#
Both Make and Python PyDoit offer powerful solutions for automating build processes and task execution. The choice between them often depends on the specific requirements of a project, such as the programming language used, the complexity of the task, and the user’s familiarity with Python. While Make is more traditional and widely used in compiling, PyDoit provides a more flexible and Python-centric approach to task automation.