Example: Connecting to the WRDS Platform With Python#
The wrds Python package is a tool designed to facilitate data retrieval from the Wharton Research Data Services (WRDS) database.
It provides direct access to the WRDS database, allowing users to programmatically query and retrieve data.
The package supports a simple Python API as well as the ability to send raw SQL queries.
Retrieved data can be easily converted into Pandas DataFrames.
Secure access to the WRDS database is managed through user authentication, ensuring data security and compliance with usage policies.
Installation#
The package can be installed via pip:
pip install wrds
To use the package, one would typically import it in Python, authenticate with WRDS credentials, and then proceed with data queries and analysis. This notebook walks through some of these basic features.
Usage#
Here are some helpful links to learn how to use the wrds Python package:
Import and Establish Connection#
Establish connection with WRDS server.
Log in using your WRDS username and password.
Set up a pgpass file to store the info. This will allow you to access WRDS without supplying your password each time, as long as you supply your username (which we are doing below via environment variables). We want to be able to access WRDS without a password so that we can automate the query.
from settings import config
from pathlib import Path
OUTPUT_DIR = Path(config("OUTPUT_DIR"))
DATA_DIR = Path(config("DATA_DIR"))
WRDS_USERNAME = config("WRDS_USERNAME")
import wrds
db = wrds.Connection(wrds_username=WRDS_USERNAME)
Loading library list...
Done
# The `obs` keyword argument limits the number of rows returned.
# You can omit it to get all rows.
df = db.get_table(library='crsp', table='msf', columns=['cusip', 'permno', 'date', 'shrout', 'prc', 'ret', 'retx'], obs=10)
df
| cusip | permno | date | shrout | prc | ret | retx | |
|---|---|---|---|---|---|---|---|
| 0 | 68391610 | 10000 | 1985-12-31 | NaN | None | None | None |
| 1 | 68391610 | 10000 | 1986-01-31 | 3680.0 | -4.37500 | None | None |
| 2 | 68391610 | 10000 | 1986-02-28 | 3680.0 | -3.25000 | -0.257143 | -0.257143 |
| 3 | 68391610 | 10000 | 1986-03-31 | 3680.0 | -4.43750 | 0.365385 | 0.365385 |
| 4 | 68391610 | 10000 | 1986-04-30 | 3793.0 | -4.00000 | -0.098592 | -0.098592 |
| 5 | 68391610 | 10000 | 1986-05-30 | 3793.0 | -3.10938 | -0.222656 | -0.222656 |
| 6 | 68391610 | 10000 | 1986-06-30 | 3793.0 | -3.09375 | -0.005025 | -0.005025 |
| 7 | 68391610 | 10000 | 1986-07-31 | 3793.0 | -2.84375 | -0.080808 | -0.080808 |
| 8 | 68391610 | 10000 | 1986-08-29 | 3793.0 | -1.09375 | -0.615385 | -0.615385 |
| 9 | 68391610 | 10000 | 1986-09-30 | 3793.0 | -1.03125 | -0.057143 | -0.057143 |
Exploring the Data#
As described here,
Data at WRDS is organized in a hierarchical manner by vendor (e.g. crsp), referred to at the top-level as libraries. Each library contains a number of component tables or datasets (e.g. dsf) which contain the actual data in tabular format, with column headers called variables (such as date, askhi, bidlo, etc).
You can analyze the structure of the data through its metadata using the wrds module, as outlined in the following steps:
List all available libraries at WRDS using list_libraries()
Select a library to work with, and list all available datasets within that library using list_tables()
Select a dataset, and list all available variables (column headers) within that dataset using describe_table()
NOTE: When referencing library and dataset names, you must use all lowercase.
Alternatively, a comprehensive list of all WRDS libraries is available at the Dataset List. This resource provides a listing of each library, their component datasets and variables, as well as a tabular database preview feature, and is helpful in establishing the structure of the data you’re looking for in an easy manner from a Web browser.
Determine the libraries available at WRDS:
sorted(db.list_libraries())[0:10]
['aha_sample',
'ahasamp',
'audit',
'audit_acct_os',
'audit_audit_comp',
'audit_common',
'audit_corp_legal',
'auditsmp',
'auditsmp_all',
'bank']
This will list all libraries available at WRDS in alphabetical order. Though all libraries will be shown, you must have a valid, current subscription for a library in order to access it via Python, just as with SAS or any other supported programming language at WRDS. You will receive an error message indicating this if you attempt to query a table to which your institution does not have access.
To determine the datasets within a given library:
db.list_tables(library="crsp")[0:10]
['acti',
'asia',
'asib',
'asic',
'asio',
'asix',
'bmdebt',
'bmheader',
'bmpaymts',
'bmquotes']
Where ‘library; is a dataset, such as crsp or comp, as returned from step 1 above.
To determine the column headers (variables) within a given dataset:
db.describe_table(library="crsp", table="msf")
Approximately 5150989 rows in crsp.msf.
| name | nullable | type | comment | |
|---|---|---|---|---|
| 0 | cusip | True | VARCHAR(8) | CUSIP Header |
| 1 | permno | True | INTEGER | PERMNO |
| 2 | permco | True | INTEGER | PERMCO |
| 3 | issuno | True | INTEGER | Nasdaq Issue Number |
| 4 | hexcd | True | SMALLINT | Exchange Code Header |
| 5 | hsiccd | True | INTEGER | Standard Industrial Classification Code Header |
| 6 | date | True | DATE | Date of Observation |
| 7 | bidlo | True | NUMERIC(11, 5) | Bid or Low Price |
| 8 | askhi | True | NUMERIC(11, 5) | Ask or High Price |
| 9 | prc | True | NUMERIC(11, 5) | Price or Bid/Ask Average |
| 10 | vol | True | NUMERIC(10, 0) | Volume |
| 11 | ret | True | NUMERIC(10, 6) | Returns |
| 12 | bid | True | NUMERIC(11, 5) | Bid |
| 13 | ask | True | NUMERIC(11, 5) | Ask |
| 14 | shrout | True | DOUBLE PRECISION | Shares Outstanding |
| 15 | cfacpr | True | DOUBLE PRECISION | Cumulative Factor to Adjust Prices |
| 16 | cfacshr | True | DOUBLE PRECISION | Cumulative Factor to Adjust Shares/Vol |
| 17 | altprc | True | NUMERIC(11, 5) | Price Alternate |
| 18 | spread | True | NUMERIC(10, 5) | Spread Between Bid and Ask |
| 19 | altprcdt | True | DATE | Alternate Price Date |
| 20 | retx | True | NUMERIC(10, 6) | Returns without Dividends |
Where ‘library’ is a dataset such as crsp as returned from #1 above and ‘table’ is a component database within that library, such as msf, as returned from query #2 above. Remember that both the library and the dataset are case-sensitive, and must be all-lowercase.
Alternatively, a comprehensive list of all WRDS libraries is available via the WRDS Dataset List. This online resource provides a listing of each library, their component datasets and variables, as well as a tabular database preview feature, and is helpful in establishing the structure of the data you’re looking for in an easy, web-friendly manner.
By examining the metadata available to us – the structure of the data – we’ve determined how to reference the data we’re researching, and what variables are available within that data. We can now perform our actual research, creating data queries, which are explored in depth in the next section.
Querying WRDS Data#
Continue the walkthrough provided here: https://wrds-www.wharton.upenn.edu/pages/support/programming-wrds/programming-python/querying-wrds-data-python/
Using get_table#
# The `obs` keyword argument limits the number of rows returned.
# You can omit it to get all rows.
df = db.get_table(library='crsp', table='msf', columns=['cusip', 'permno', 'date', 'shrout', 'prc', 'ret', 'retx'], obs=10)
df
| cusip | permno | date | shrout | prc | ret | retx | |
|---|---|---|---|---|---|---|---|
| 0 | 68391610 | 10000 | 1985-12-31 | NaN | None | None | None |
| 1 | 68391610 | 10000 | 1986-01-31 | 3680.0 | -4.37500 | None | None |
| 2 | 68391610 | 10000 | 1986-02-28 | 3680.0 | -3.25000 | -0.257143 | -0.257143 |
| 3 | 68391610 | 10000 | 1986-03-31 | 3680.0 | -4.43750 | 0.365385 | 0.365385 |
| 4 | 68391610 | 10000 | 1986-04-30 | 3793.0 | -4.00000 | -0.098592 | -0.098592 |
| 5 | 68391610 | 10000 | 1986-05-30 | 3793.0 | -3.10938 | -0.222656 | -0.222656 |
| 6 | 68391610 | 10000 | 1986-06-30 | 3793.0 | -3.09375 | -0.005025 | -0.005025 |
| 7 | 68391610 | 10000 | 1986-07-31 | 3793.0 | -2.84375 | -0.080808 | -0.080808 |
| 8 | 68391610 | 10000 | 1986-08-29 | 3793.0 | -1.09375 | -0.615385 | -0.615385 |
| 9 | 68391610 | 10000 | 1986-09-30 | 3793.0 | -1.03125 | -0.057143 | -0.057143 |
Using raw_sql#
df = db.raw_sql(
"""
SELECT
cusip, permno, date, shrout, prc, ret, retx
FROM
crsp.msf
LIMIT 10
""",
date_cols=['date']
)
df
| cusip | permno | date | shrout | prc | ret | retx | |
|---|---|---|---|---|---|---|---|
| 0 | 68391610 | 10000 | 1985-12-31 | NaN | NaN | NaN | NaN |
| 1 | 68391610 | 10000 | 1986-01-31 | 3680.0 | -4.37500 | NaN | NaN |
| 2 | 68391610 | 10000 | 1986-02-28 | 3680.0 | -3.25000 | -0.257143 | -0.257143 |
| 3 | 68391610 | 10000 | 1986-03-31 | 3680.0 | -4.43750 | 0.365385 | 0.365385 |
| 4 | 68391610 | 10000 | 1986-04-30 | 3793.0 | -4.00000 | -0.098592 | -0.098592 |
| 5 | 68391610 | 10000 | 1986-05-30 | 3793.0 | -3.10938 | -0.222656 | -0.222656 |
| 6 | 68391610 | 10000 | 1986-06-30 | 3793.0 | -3.09375 | -0.005025 | -0.005025 |
| 7 | 68391610 | 10000 | 1986-07-31 | 3793.0 | -2.84375 | -0.080808 | -0.080808 |
| 8 | 68391610 | 10000 | 1986-08-29 | 3793.0 | -1.09375 | -0.615385 | -0.615385 |
| 9 | 68391610 | 10000 | 1986-09-30 | 3793.0 | -1.03125 | -0.057143 | -0.057143 |
df = db.raw_sql(
"""
SELECT
a.gvkey, a.datadate, a.tic, a.conm, a.at, a.lt, b.prccm, b.cshoq
FROM
comp.funda a
JOIN
comp.secm b ON a.gvkey = b.gvkey AND a.datadate = b.datadate
WHERE
a.tic = 'IBM' AND
a.datafmt = 'STD' AND
a.consol = 'C' AND
a.indfmt = 'INDL'
LIMIT 10
"""
)
df
| gvkey | datadate | tic | conm | at | lt | prccm | cshoq | |
|---|---|---|---|---|---|---|---|---|
| 0 | 006066 | 1962-12-31 | IBM | INTL BUSINESS MACHINES CORP | 2112.301 | 731.700 | 389.9996 | NaN |
| 1 | 006066 | 1963-12-31 | IBM | INTL BUSINESS MACHINES CORP | 2373.857 | 782.119 | 506.9994 | NaN |
| 2 | 006066 | 1964-12-31 | IBM | INTL BUSINESS MACHINES CORP | 3309.152 | 1055.072 | 409.4995 | NaN |
| 3 | 006066 | 1965-12-31 | IBM | INTL BUSINESS MACHINES CORP | 3744.917 | 1166.771 | 498.9991 | NaN |
| 4 | 006066 | 1966-12-31 | IBM | INTL BUSINESS MACHINES CORP | 4660.777 | 1338.149 | 371.4997 | NaN |
| 5 | 006066 | 1967-12-31 | IBM | INTL BUSINESS MACHINES CORP | 5598.668 | 1767.067 | 626.9995 | NaN |
| 6 | 006066 | 1968-12-31 | IBM | INTL BUSINESS MACHINES CORP | 6743.430 | 2174.291 | 314.9998 | NaN |
| 7 | 006066 | 1969-12-31 | IBM | INTL BUSINESS MACHINES CORP | 7389.957 | 2112.967 | 364.4994 | 113.717 |
| 8 | 006066 | 1970-12-31 | IBM | INTL BUSINESS MACHINES CORP | 8539.047 | 2591.909 | 317.7496 | 114.587 |
| 9 | 006066 | 1971-12-31 | IBM | INTL BUSINESS MACHINES CORP | 9576.219 | 2933.837 | 336.4996 | 115.534 |
params = {"tickers": ("0015B", "0030B", "0032A", "0033A", "0038A")}
df = db.raw_sql(
"""
SELECT
datadate, gvkey, cusip
FROM comp.funda
WHERE
tic IN %(tickers)s
LIMIT 10
""",
params=params,
)
df
| datadate | gvkey | cusip | |
|---|---|---|---|
| 0 | 1982-10-31 | 002484 | 121579932 |
| 1 | 1983-10-31 | 002484 | 121579932 |
| 2 | 1984-10-31 | 002484 | 121579932 |
| 3 | 1985-10-31 | 002484 | 121579932 |
| 4 | 1986-10-31 | 002484 | 121579932 |
| 5 | 1987-10-31 | 002484 | 121579932 |
| 6 | 1988-10-31 | 002484 | 121579932 |
| 7 | 1989-06-30 | 002484 | 121579932 |
| 8 | 1990-06-30 | 002484 | 121579932 |
| 9 | 1991-06-30 | 002484 | 121579932 |
When you are done with your queries, you should close the connection to the WRDS server. This can be done by calling the close() method on the db object.
db.close()
Creating a .pgpass file#
In this course, we want to be able to automate our data pulls. One obstacle to this is that we need to supply our password each time we run a query. To avoid this, the wrds package makes it easy to create a .pgpass file. With a .pgpass file, we can access WRDS without a password. We will subsequently only need to supply our username, via wrds_username=WRDS_USERNAME. As you will see, we will save our WRDS_USERNAME in the .env file, so as to avoid hardcoding it in the source code. (Recall that the .env file is a file that contains environment variables used by the project and that the .env is not tracked by git because we have it in the .gitignore file.)
Create a .pgpass file as follows:
from settings import config
# Make sure that you have included the line
# WRDS_USERNAME = your_wrds_username
# in the .env file
WRDS_USERNAME = config("WRDS_USERNAME")
print(WRDS_USERNAME) # Make sure that the username is correct
db = wrds.Connection(wrds_username=WRDS_USERNAME)
Once you run this code for the first time, you will be asked to supply your password. After you supply your password, you will be asked to create a .pgpass file. Select yes. This should create a .pgpass file on your computer.
Note that if you do this in Visual Studio Code in an interactive window, the prompt for your username and password will appear at the top of the window (see screenshot below).
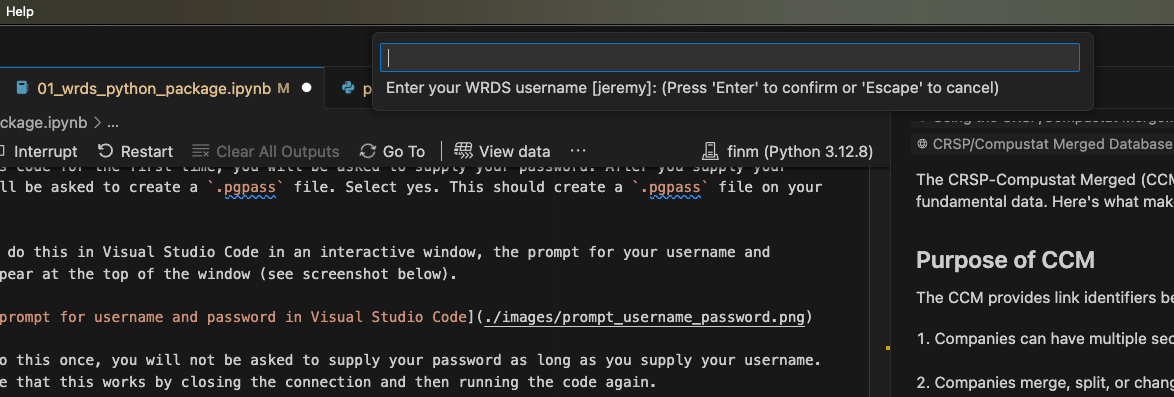
As long as you do this once, you will not be asked to supply your password as long as you supply your username. Test to make sure that this works by closing the connection and then running the code again.
db = wrds.Connection(wrds_username=WRDS_USERNAME)
Loading library list...
Done
db.close()
# This subsequent run should work without a password.
db = wrds.Connection(wrds_username=WRDS_USERNAME)
Loading library list...
Done
Misc#
data = db.get_row_count('djones', 'djdaily')
data
28073
db.close()